Optimising Python programs with py-spy and timeit
Jun 14, 2024 by Raphaël Simon | 4497 views
https://cylab.be/blog/345/optimising-python-programs-with-py-spy-and-timeit
Reinforcement Learning environments need to be as fast as possible such that the agent can execute many steps in a very short amount of time. This is important since some problems the agent requires several million or even billions of steps before it converges.
While testing a variant of Proximal Policy Optimisation (PPO), Masked PPO, I noticed that it was running slower than standard PPO. This lead me to start investigating whether there was any code of the environment that could be optimised.
Our target environment is the Network Attack Simulator (NASim). It is designed to be used for rapid testing of autonomous pen-testing agents using reinforcement learning and planning. And as we mentioned above, we need to make sure it is fast.
For our first test we use a program which trains an agent using PPO from the stable-baselines3 repository on NASim. This will be our baseline which we will compare against MaskedPPO from stable-baselines3-contrib.
py-spy
We start off with py-spy, a sampling profiler for Pyhon programs. It has an extremely low overhead and you don’t need to modify you code. You just give it the pid of the running process or the program to start, and that’s it.
Using py-spy is very easy. We can either output an SVG image file of the recorded profile, display a view like top to show which functions are taking the most time, or display the current call stack for each python thread with dump.
What we want in our case is the top command, as we want to know whether there are function from the simulator which take a significant time. We can launch it with:
py-spy top -- python nasim_small_ppo.py
Then we can press 4 to sort by total time, or ? for the help menu and find further commands.

We let it run for a few minutes to have a good understanding of what consumes the most time. Since we’re training an agent, the code loops over the same functionalities again and again. This means we’re not required to let it run till the end. Then we can start the comparison with the MaskedPPO algorithm:

We can actually see that the action_masks function from the environment, which MaskedPPO makes use of, takes up a significant mount of time compared to other functions from the environment, which are nowhere near the top time consumers in our baseline.
timeit
Having identified the slow function, we can now look at the implementation and then see whether we can come up with an optimisation.
def action_masks(self):
"""Get a vector mask for valid actions. The mask is based on whether
a host has been discovered or not.
Returns
-------
ndarray
numpy vector of 1's and 0's, one for each action. Where an
index will be 1 if action is valid given current state, or
0 if action is invalid.
"""
assert isinstance(self.action_space, FlatActionSpace), \
"Can only use action mask function when using flat action space"
mask = np.zeros(self.action_space.n, dtype=np.int64)
for a_idx in range(self.action_space.n):
action = self.action_space.get_action(a_idx)
if self.current_state.get_host(action.target).discovered:
mask[a_idx] = 1
return mask
The code goes over all actions and for each of them, looks at whether the target host has been discovered, and then sets the mask accordingly. This can take a long time if we have a large amount of actions. We can replace it with a more NumPy-centric approach that exploits the fact that all hosts share the same number of actions for the scenarios we use:
# Create a list of bools telling is uf host i has been discovered
discovered = [h[1].discovered for h in self.current_state.hosts]
num_actions_per_host = self.action_space.n / len(discovered)
assert self.action_space.n / num_actions_per_host == len(discovered), \
"Hosts don't all have the same amout of actions"
# Repeat the bool num_actions_per_host times
mask = np.repeat(discovered, num_actions_per_host)
return mask
To test the code we use the timeit module. First, we write a setup code which prepares the function we want to test. In our case, the environment first has to be created, and therefore the necessary libraries need to be imported. The statement then contains the actual function which we want to benchmark. We decided to run the function 100.000 times to obtain a good approximation of the execution time.
setup_code = """
import gymnasium as gym
import nasim
env = gym.make('SmallGenLasPO-v0')
obs, _ = env.reset()
"""
stmt_old_mask = "env.unwrapped.get_action_mask()"
stmt_new_mask = "env.unwrapped.action_masks()"
execution_time_old = timeit.timeit(stmt_old_mask, setup=setup_code, number=100_000)
print(f"Execution time for old version: {execution_time_old} seconds")
execution_time_new = timeit.timeit(stmt_new_mask, setup=setup_code, number=100_000)
print(f"Execution time for new version: {execution_time_new} seconds")
Here is the result:
Execution time for old version: 10.287292759021511 seconds
Execution time for new version: 0.4495102990185842 seconds
Astonishing. We have sped up the code by over an order of magnitude. Now we just need to build the environment with the implemented code change and test whether it really works as expected. Lets’ check:
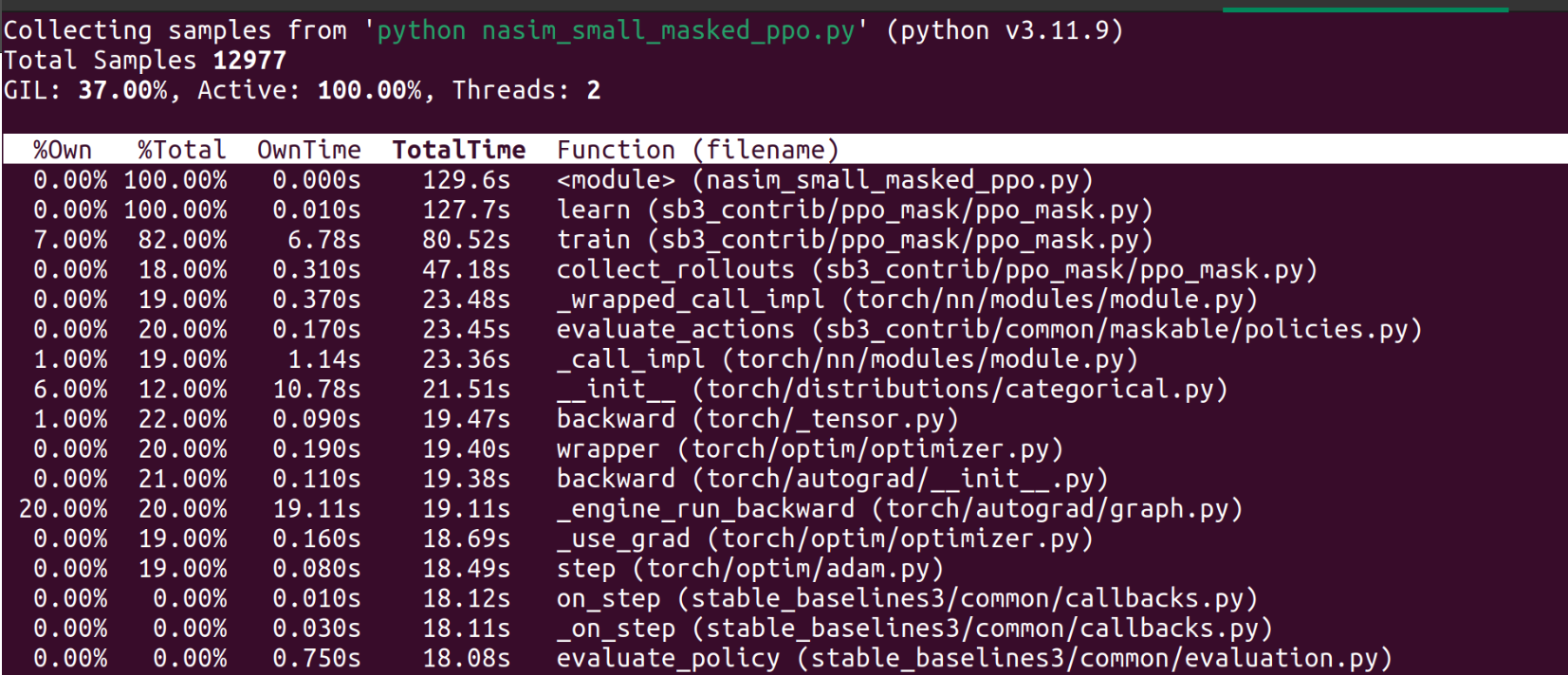
Wonderful. We have indeed reduced the execution time of the action_masks method. It’s no longer part of the biggest consumers, in fact, I cannot even see it in the entire output.
We hope this blog post was helpful to and you were able to learn something new, or even apply it to your own code!
This blog post is licensed under
CC BY-SA 4.0


