Linux kernel threads and processes management : task_struct
Jun 26, 2024 by Thibault Debatty | 14857 views
https://cylab.be/blog/347/linux-kernel-threads-and-processes-management-task-struct
In a previous blog post, I have shown how to create a Linux kernel module. This time I will show how the Linux kernel uses a task_struct to manage threads and processes. To illustrate, I will show how a kernel module can access and alter these, and thus also alter the inner working of the Linux kernel.

Prerequisites
To illustrate this blog post, I will show you how to create and compile a kernel module that will alter the list of task_struct which the kernel uses to manage running threads and processes.
Warning: I strongly recommend running these experiments on a dedicated VM, as any mistake might crash or break your system, and cause data loss!
To compile this module you will need a few tools:
sudo apt install -y build-essential libncurses-dev flex bison libelf-dev libssl-dev
And you’ll also need the headers of the target kernel. If you are using the stock Ubuntu kernel, and want to compile the module for yourself, you can install these headers with:
sudo apt install linux-headers-`uname -r`
task_struct
In the Linux kernel, each process and thread is described using a task_struct. Indeed, in Linux a thread is considered as a standard process that shares certain resources (like paging tables and signal handlers) with other processes.
The task_struct is defined in linux/sched.h. With the current version of the kernel (6.9.6), this starts at line 748:
https://elixir.bootlin.com/linux/v6.9.6/source/include/linux/sched.h#L748
This struct counts a lot of fields, some of which depend on kernel configuration options. For example, the CONFIG_SMP kernel configuration option enables kernel support for Symmetric Multi-Processing (hence support for computers with multiple CPUs), which appends required fields to the task_struct:
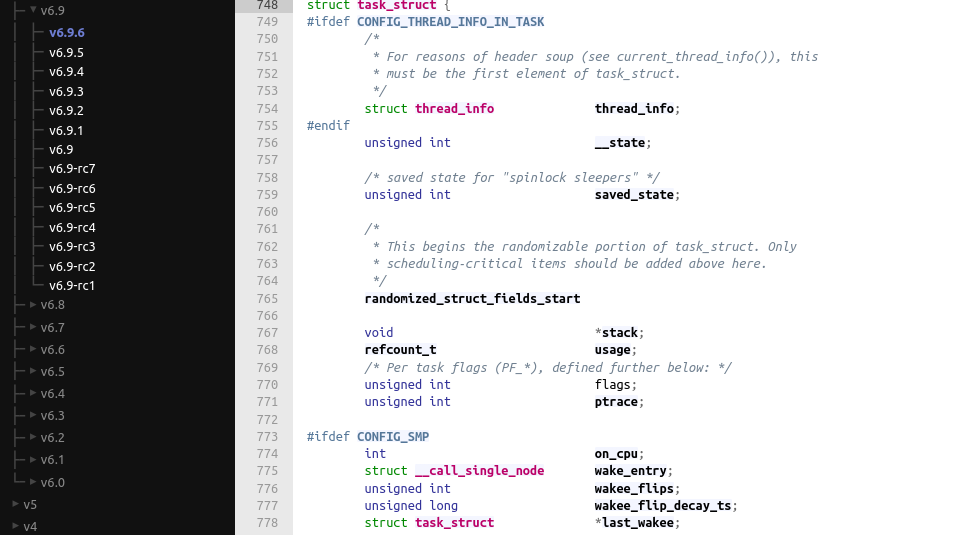
I let you check the documentation to find all available fields. Here are the main ones, which I’ll use in my custom kernel module below:
pidis actually misleading : as the Linux kernel maintains atask_structfor each thread, thepidis actually the thread id;tgid(Task Group ID) is the actual PID: you can also define this field as thepidof the main thread of each process;commis the executable name, excluding path, and limited to (usually) 16 characters.
Process tree
The task_struct contains different fields that allow to maintain and navigate the process tree:
task_struct *parentis a pointer to thetask_structof parent process;list_head childrenis a doubly-linked list of children processes;list_head sibling: processes that are all direct children of the same parent are maintained in thesiblingdoubly-linked list.
Lists
There are also other lists and pointers that are used for example to iterate of threads and processes:
task_struct *group_leaderpoints to themainthread of group of threads (thus thetask_structrepresenting the process);list_head tasksis a doubly-linked list of alltask_struct(all threads);
Finally, the task_struct contains a signal_struct *signal that itself keeps a doubly-linked list of threads, which is used to loop over the threads of the same process.
https://elixir.bootlin.com/linux/v6.9.6/source/include/linux/sched/signal.h#L99
This makes looping over all processes and threads a little intricate, as we will see in the example below.
kernel module
In kernel space (in a kernel module), we can use the for_each_process_thread(p, t) macro to loop over all the threads (represented by a task_struct).
In the example below, I will loop over the tasks list to modify the name of the systemd process. To test and play, you can create a kernel module called tasks.c with the following content:
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
MODULE_LICENSE("Dual MIT/GPL");
static int __init tasks_init(void)
{
pr_info("%8s %8s %16s %8s", "PID", "TGID", "COMM", "PRIO");
struct task_struct *p = NULL, *t = NULL;
// use Read-copy-update (RCU) to lock the list while we
// traverse
rcu_read_lock();
for_each_process_thread(p, t) {
// lock the process task_struct while we access fields
task_lock(p);
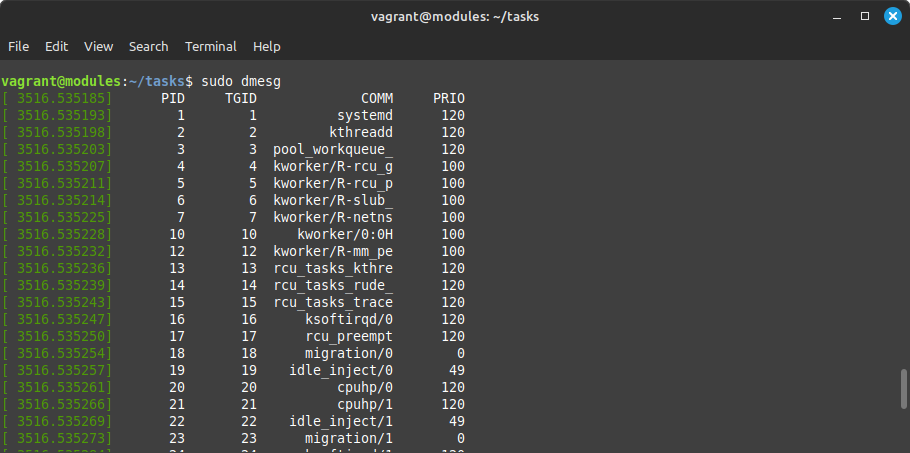
pr_info("%8d %8d %16s %8d", t->pid, t->tgid, t->comm, t->prio);
// change the name of systemd process
if (strcmp(t->comm, "systemd") == 0) {
strcpy(t->comm, "hidden");
}
task_unlock(p);
}
rcu_read_unlock();
return 0;
}
static void __exit tasks_exit(void)
{
pr_info("Bye!\n");
}
module_init(tasks_init);
module_exit(tasks_exit);
Just like in the previous blog post, you can create the following Makefile to build the code:
PWD := $(shell pwd)
KDIR := /lib/modules/$(shell uname -r)/build/
obj-m += tasks.o
modules:
make -C $(KDIR) M=$(PWD) modules
clean:
make -C $(KDIR) M=$(PWD) clean
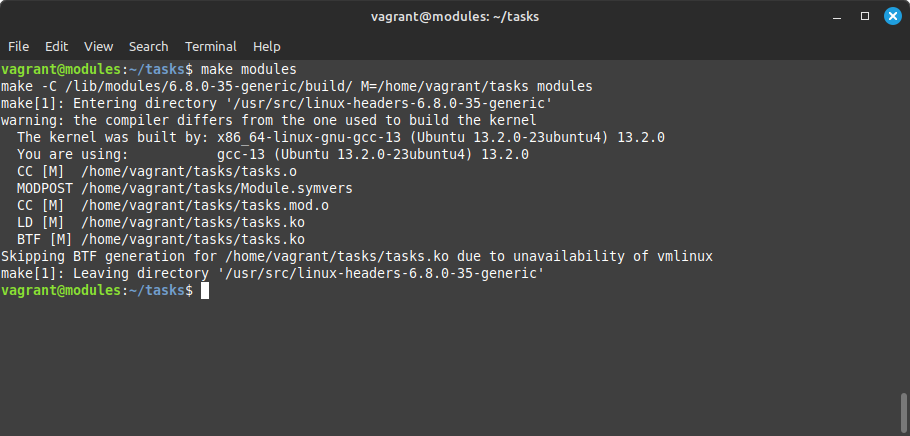
You can now build the module with:
make modules
Test
To test our module, let’s first look at the process tree:
pstree -a | head

Load the kernel module:
sudo insmod tasks.ko
Check kernel messages:
sudo dmesg
And use pstree again to check the new name of systemd:
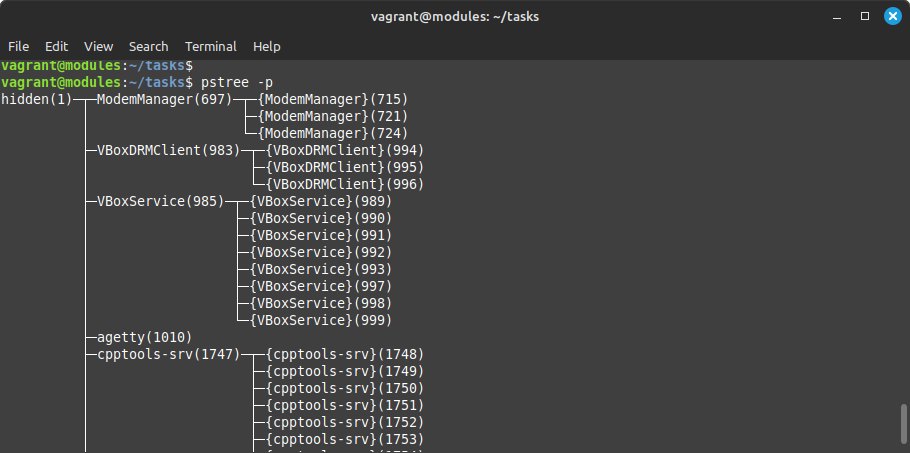
Notice that we did not use any syscall to modify the kernel internal structures. This makes protection and detection more complicated, and is the principle of kernel rootkits.
This blog post is licensed under
CC BY-SA 4.0


