Data deduplication
Jan 22, 2025 by Thibault Debatty | 3225 views
In the last years, the price of data storage has dropped significantly. However, in the same time the amount of produced data has literally exploded. Moreover, a lot of stored data is actually copies of each other.
For instance, the disk images of different virtual machines that run the same OS will likely share large portions of identical data. Similarly, multiple backups of the same files on the same disk may also exist. As a result, one may be inclined to remove the duplicated files in some way to spare some disk space.
The principle may seem simple, but there are actually multiple ways to do so, each with caveats. In this blog post I will briefly expose the different possibilities, and show a hands on example using the tool rdfind.
inodes and hardlinks
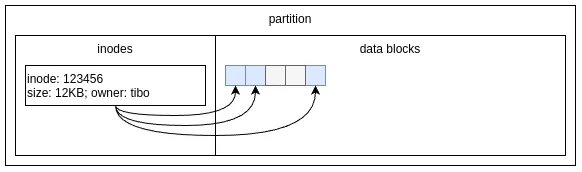
But first some theory is required to understand the pros and cons of each method. In all modern filesystems, the content of files is stored in data blocks, which are usually 4KB in size. So a single file will typically span over multiple data blocks, which are not necessarily contiguous. To keep track of all this, filesystems use an index where each file is described by a data structure usually called an inode. In Windows NTFS, the equivalent of an inode is a Master File Table (MFT) entry.
So an inode is a data structure that describes a file (usually one, sometimes more), and contains a reference to the data blocks that contain the file’s content. The inode also store the file’s metadata such as the file size, permissions, owner, creation date, etc.
⚠ A fixed number of inodes is created when you format the partition. In some (rare) cases your disk may appear full because all inodes are used (but not all data block). You can check the number of available inodes with
df -i -h
In most filesystems, a directory is considered as an ordinary file, with an inode and data blocks. The sole difference is that the data blocks of a directory store the names and inode numbers of its children (i.e. the files and subdirectories that it contains).
As we stated previously, an inode usually describes a single file … except when you create a hardlink. A hardlink is a directory entry that points to an already existing inode
⚠ Usually you cannot create a hardlink to a directory as this could create a loop in the filesystem.
Here is a simple example:
touch file.txt
ln file.txt hardlink.txt
The inode and data blocks of file.txt and hardlink.txt are the same:
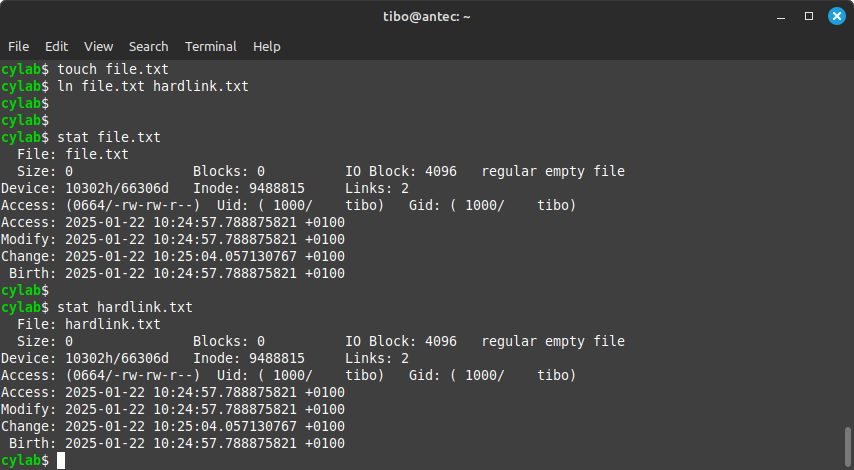
For a regular user, both files appear as regular files, except when one file is modified, the other is also modified. They are mirrors of each other.
Block level deduplication
Now let’s look at practical solutions for data deduplication. The first one is block-level deduplication. This feature is available in only a few filesystems, like ZFS. As the name state, it operates at the block level: identical data blocks are stored only once, and common components are shared between files. In my previous example of virtual machine drives, ZFS can detect the blocks that are identical between multiple virtual drives, and store them only once. If multiple complete files are identical, ZFS will likewize store only one copy. The process allows to reduce storage size and is fully transparent for the user, but it comes with a serious performance and memory penalty.
Indeed, for each write operation, the OS must compare the hash of the block to be written with the hash of every block that has already been written. This comparison can be time-consuming, especially as the deduplication table (DDT) grows larger. Also, enabling deduplication requires a significant amount of memory to store the DDT. It is generally recommended to have at least 1 GB of RAM per 1 TB of storage.
Copy-on-write (CoW)
Copy-on-write (CoW) is a feature offered by the Btrfs filesystem, where a copy of a file is initially a copy of the inode only, with read-only pointers to the data blocks of the original file. It’s only when data is written to the file that a copy of the concerned data blocks is created, hence the name copy-on-write.
This feature allows to reduce disk usage when a user creates copies of data, like a backup of one or more files on the same partition. Additionally, the copy operation occurs almost instantly, as only the inodes need to be copied.
The drawback of copy-on-write is that it only works when copying files on the same partition. For example, if you have a Btrfs drive that you use to store your backups, and you copy multiple times the same file from your main drive to your backup drive, CoW will be helpless and your backup drive will store multiple copies of the data.
File-level deduplication and rdfind
Finally, some tools allow to perform file-level deduplication : search identical files and replaces copies with hardlinks to the original file. However this is a crucial consideration: as files are now mirrors of each other, modifying one file effectively changes all of them. So this solution is (in my opinion) only suitable for archives that will never be altered.
One such tool is rdfind (redundant data find).
You can usually install rdfind from your repository:
sudo apt install rdfind
The basic command is
rdfind /path/to/directory
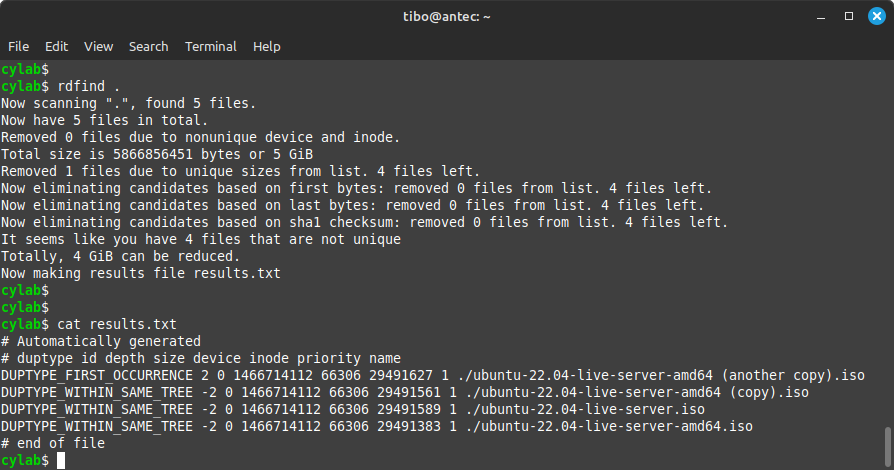
Without additional parameters, rdfind simply lists duplicate files and create a report result.txt. The nice thing is the algorithm is pretty clever to read as little as possible from the disk, and reduce processing time:
- Recursively read the directory to create a list a possibly duplicates, with the name and size of each file. This can happen fast as the size of files is stored in inodes, so the file content is not read at this time.
- From the list of possibly duplicates, remove files with a unique size.
- Sort the list by inode number, this way files are processed according to inode number, which should roughly correspond to block number, and thus reduce seek times for spinning disks.
- Read the first few bytes of each file, and remove unique files from the list.
- Read the last few bytes of each file, and remove unique files.
- Finally, read the full content of files and compute a hash.
- Remove files that have a unique hash.
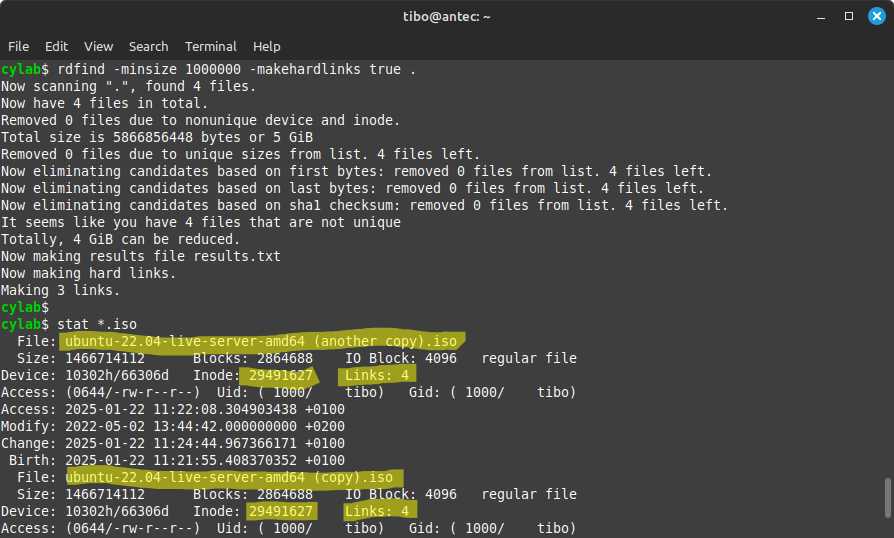
Once you are sure, you can ask rdfind to replace copies by hardlinks. Also, to further reduce processing time you can ignore files smaller then 1MB:
rdfind -minsize 1000000 -makehardlinks true /path/to/directory
This blog post is licensed under
CC BY-SA 4.0


