MARk : use built-in file data source
Jul 15, 2021 by Thibault Debatty | 2849 views
https://cylab.be/blog/115/mark-use-built-in-file-data-source
The Multi-Agent Ranking framework (MARk) allows to quickly build ranking and detection systems by combing building blocks. In this blog post, we show how to use the file data source to inject data into the system…
Installation
Easiest way to run MARk is using docker-compose. So first create a dedicated directory, you can call it mark and create a subdirectory called modules:
mkdir mark
cd mark
mkdir modules
Now, in the mark directory, create a file called *docker-compose.yml with following content:
version: '2.0'
services:
mark-web:
image: cylab/mark-web:1.4.5
container_name: mark-web
environment:
- MARK_HOST=mark-server
- MARK_PORT=8080
- APP_URL="http://127.0.0.1:8000"
ports:
- "8000:80"
depends_on:
- mark
mark:
image: cylab/mark:2.5.3
container_name: mark-server
volumes:
- ./modules:/mark/modules
environment:
- MARK_MONGO_HOST=mark-mongo
ports:
- "8080:8080"
depends_on:
- mongo
mongo:
image: mongo:4.4
container_name: mark-mongo
You can now start the server with:
docker-compose up
For now the server is empty as there is no data flowing in, and no detector configured…
You can stop the server with ctrl + c.
The built-in file data source
MARk supports the concept of built-in data source. These data sources are started automatically when the server starts. From a technical point of view, a built-in data source is a java class that implements the DataAgentInterface.
The current version of MARk (2.5.3) has one built-in data agent: the FileSource. The FileSource is a generic data agent that reads a file and parses it line by line using a named regular expression. So it can be used for any kind of object to be ranked. This data source takes 2 mandatory parameters:
file: the file to readregex: the named regex to use
To illustrate how this data source works, we will build an example, where:
- we use the logs of a proxy server (stored in a text file)
- the subjects of interest (that we want to rank) are the internal computers, identified by their IP address.
You can download an example log file, and save it to the modules directory, with the following command:
wget https://cylab.be/s/bIJf4 -O modules/1000_http_requests.txt
This file contains lines like these:
1472083251.488 575 198.36.158.8 TCP_MISS/200 1411 GET http://ajdd.rygxzzaid.mk/xucjehmkd.html - DIRECT/118.220.140.185 text/html
1472083251.573 920 198.36.158.8 TCP_MISS/200 765 GET http://epnazrk.wmaj.ga/zlrsmtcc.html - DIRECT/130.167.210.247 text/html
1472083251.613 444 198.36.158.8 TCP_MISS/200 755 GET http://epnazrk.wmaj.ga/zjeglwir.html - DIRECT/130.167.210.247 text/html
1472083251.658 590 198.36.158.8 TCP_MISS/200 1083 GET http://kfiger.wfltjx.cc/uxmt.html - DIRECT/47.238.242.2 text/html
1472083251.724 683 198.36.158.8 TCP_MISS/200 1419 GET http://isogbg.hgwpxah.nz/roeefw.html - DIRECT/233.4.82.7 text/html
1472083251.862 442 198.36.158.8 TCP_MISS/200 1960 GET http://rkfko.apyeqwrqg.cm/rdhufye.html - DIRECT/249.70.126.8 text/html
1472083251.938 276 198.36.158.8 TCP_MISS/200 111 GET http://ootlgeqo.fomu.ve/sfidbhq.html - DIRECT/243.179.195.173 text/html
1472083252.040 888 198.36.158.8 TCP_MISS/200 1055 GET http://qddggmg.rtvw.ru/uwwmy.html - DIRECT/79.204.34.38 text/html
1472083252.155 209 198.36.158.8 TCP_MISS/200 713 GET http://swienzd.uzqwmbs.nu/tzxpdxdq.html - DIRECT/55.214.50.166 text/html
1472083252.163 106 198.36.158.8 TCP_MISS/200 680 GET http://lisbnwk.hhafb.sb/uenyswiuf.html - DIRECT/162.217.59.67 text/html
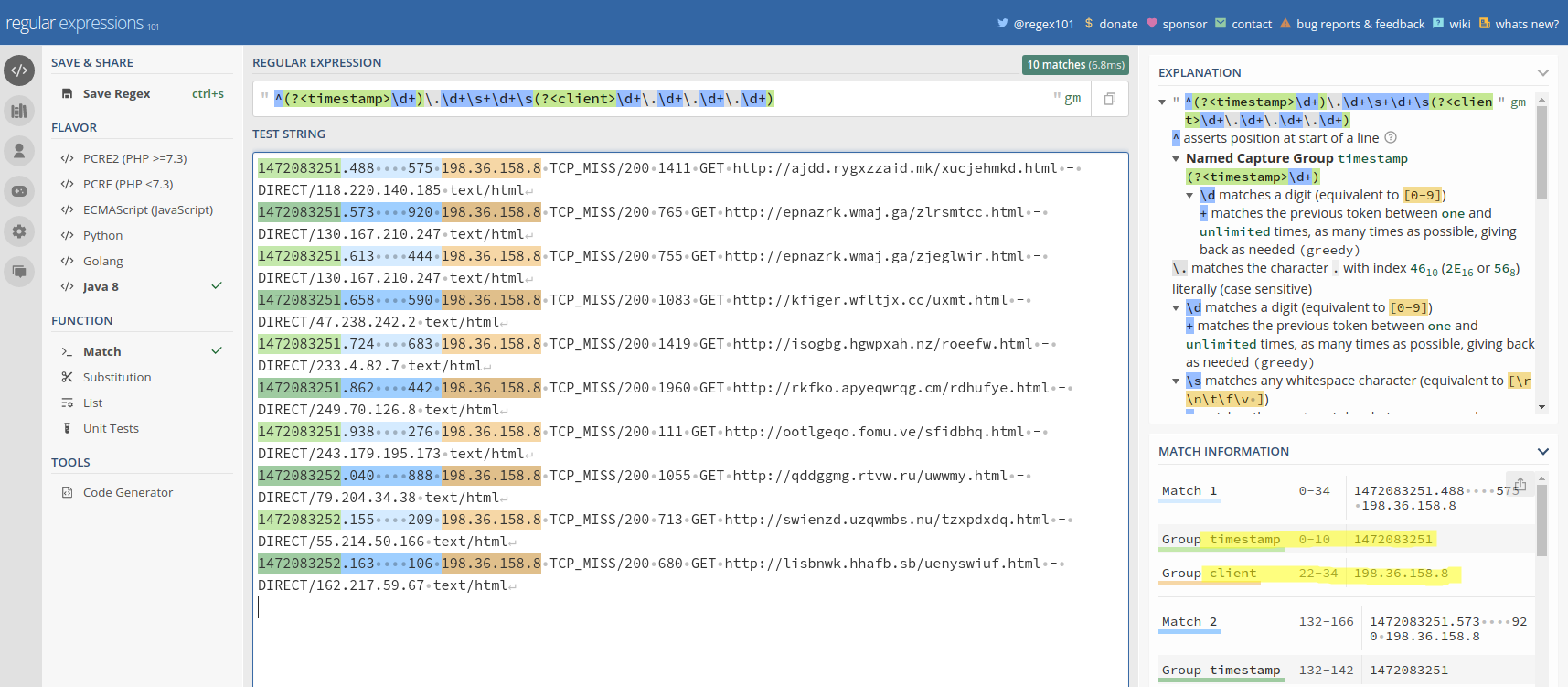
Now we must build a named regex (a regex where capture groups can receive a name), to extract from each line:
- a timestamp (in seconds);
- the different components of the subject (in our case there is only one: the IP of the client).
You can use a site like regex101.com to help you build the regex:
Now you can create the appropriate configuration file for the file data agent, that you should call file.data.yml and place in the modules directory. Pay attention that the `````` characters must be escaped:
class_name: be.cylab.mark.data.FileSource
label: data.proxy
parameters:
file: 1000_http_requests.txt
regex: "^(?<timestamp>\d+\.\d+)\s+\d+\s(?<client>\d+\.\d+\.\d+\.\d+)"
Running
Now you can start the MARk server:
docker-compose up
After a few seconds, the server will up and running, and the data agent will start reading and parsing the file.
The web interface will be available at http://127.0.0.1:8000 with following default credentials:
- E-mail:
mark-admin@cylab.be - Password:
change-me!
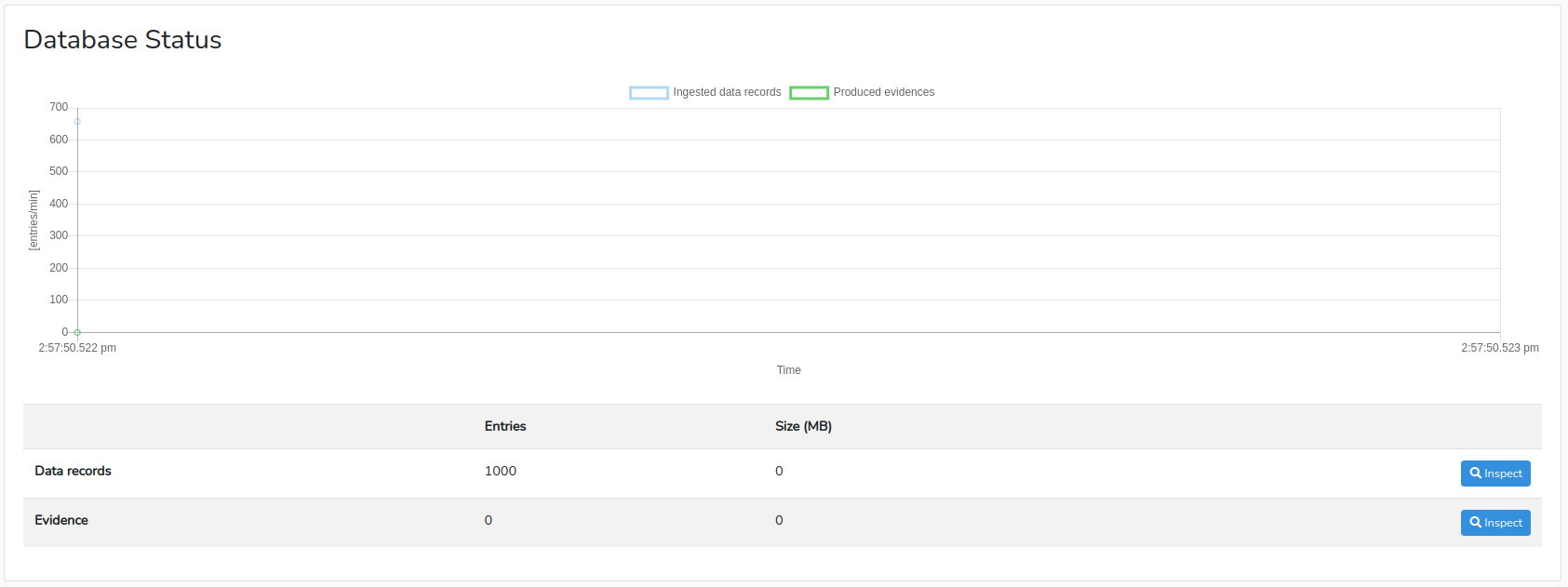
At the bottom of the Status page, you can see that the configured data source is properly listed. You can also see that the database ingested 1000 data records. Finally, by clicking on “Inspect”, we can see that the data records have been correctly parsed.
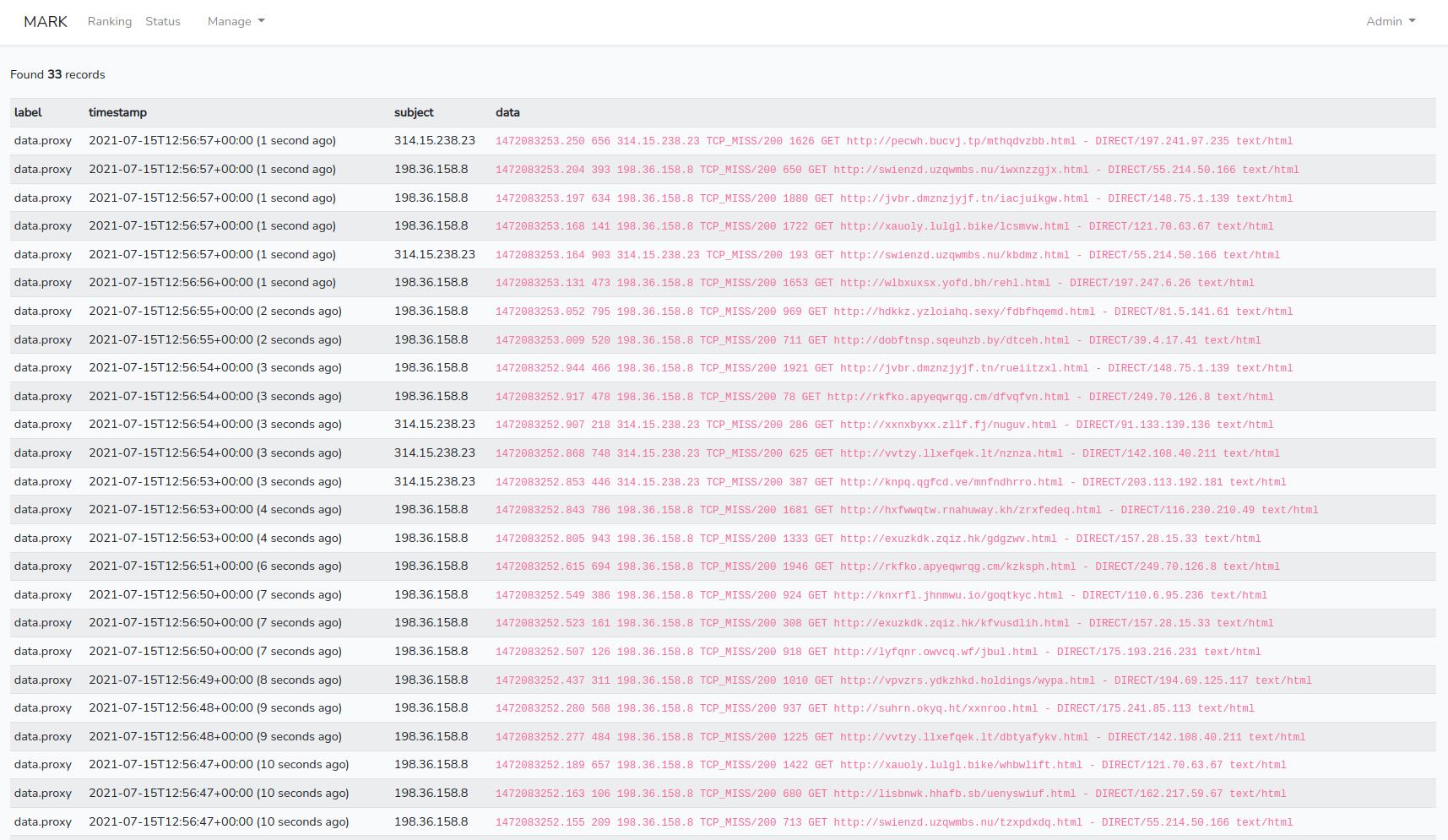
Controlling speed
However, all records seem to have the same timestamp. Indeed, by default the FileSource tries to read the file as fast as possible. To respect the time interval between lines, you can use the speed configuration parameter:
class_name: be.cylab.mark.data.FileSource
label: data.proxy
parameters:
file: 1000_http_requests.txt
regex: "^(?<timestamp>\d+\.\d+)\s+\d+\s(?<client>\d+\.\d+\.\d+\.\d+)"
speed: "1"
This time the data records will be processed according to their timestamp. In the example data file, the lines span over 8 seconds. If needed, you can even slow down processing by indicating a smaller speed value, like 0.1.
Going further
Now that data is flowing into your server, you can add and configure built-in detectors or create your own detectors to build your detection pipeline.
This blog post is licensed under
CC BY-SA 4.0


