Run your own local LLM with Ollama
Nov 18, 2024 by Thibault Debatty | 25234 views
https://cylab.be/blog/377/run-your-own-local-llm-with-ollama
Ollama is an innovative tool designed to simplify the way you work with AI models on your local machine. Much like Docker revolutionized containerized applications, Ollama provides a seamless experience for downloading, managing, and running pre-trained AI models.

This post will walk you through the installation, key features, and essential commands to get started with Ollama. You’ll also learn how it manages resources like GPU and memory, the main configuration options and how to use the Ollama API.
Installation
On a Linux system, you can install Ollama with
curl -fsSL https://ollama.com/install.sh | sh
If you have a GPU, Ollama will automatically discover and use it. Otherwise your CPU will be used, but it will be extremely slow!
First steps
Ollama has a very similar architecture to Docker: it’s actually a daemon that runs in the background, with a command line client that can be used to interact with, and a repository of pre-trained models which can be pulled and used immediately.
So the first step will be to download a model with
ollama pull <model>
For example
ollama pull llama3.2
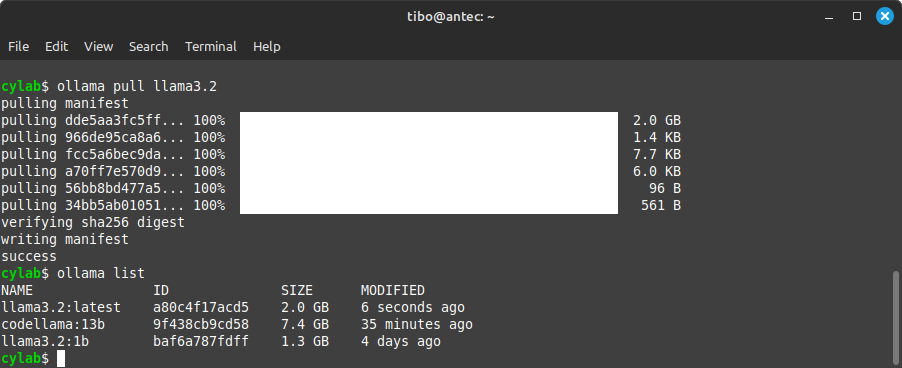
Just like Docker images, Ollama models have tags, which usually specify a number of parameters or fine-tuned version. Here is another example, for the 1 billion parameters version:
ollama pull llama3.2:1b
You can find the complete list of available models at https://ollama.com/search
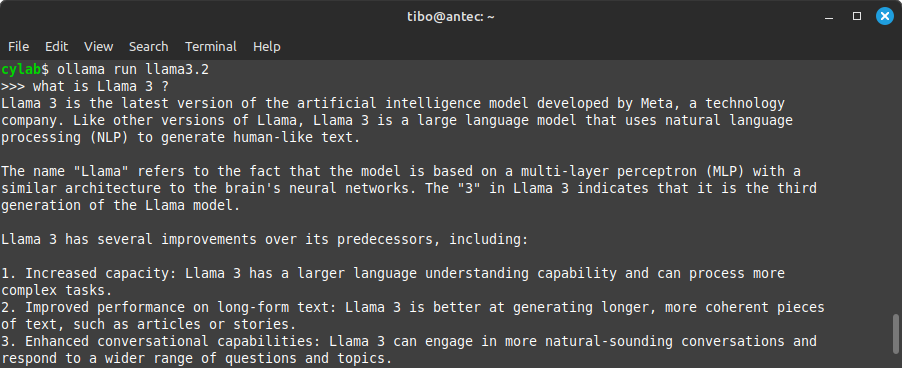
Once pulled, you can load and start a conversation with a model with:
ollama run <model>
For example
ollama run llama3.2
You can also list pulled models with
ollama list
And, if needed, you can delete a model with
ollama rm <model>
Memory management
Ollama tries to to the best with available GPU memory:
- once a model is loaded, it remains in memory (default timeout is 5 minutes), to allow faster processing of following requests;
- if a model is too large to fit in vRAM of the GPU, it will be partly loaded in system memory (RAM). This allows to run large models on a low-end GPU, at the expense of a desperately slow speed (especially with ‘older’ DDR4 memory).
For example, you can run a ‘large’ 13 billion parameters model with:
ollama pull codellama:13b
ollama run codellama:13b:
In another terminal, you can check the loaded models with
ollama ps
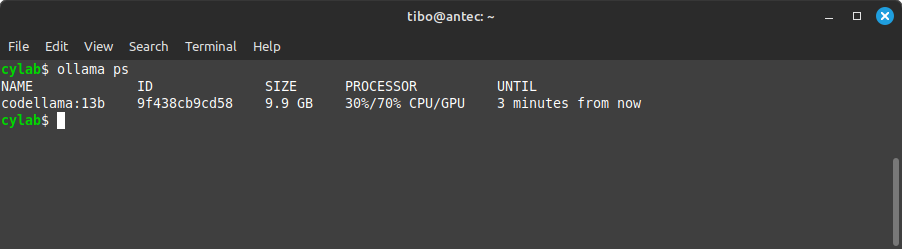
This example shows that part of the model is loaded in GPU vRAM (70%), while the rest lays in system RAM. The result is working, but extremely slow because of constant memory transfers!
Configuration
Ollama uses environment variables. So on Linux, you must
- edit systemd service configuration with
sudo systemctl edit ollama.service - add environment variables under
[Service]].
Here are a few example variables:
[Service]
# IP and port of Ollama server
Environment="OLLAMA_HOST=127.0.0.1:11434"
# Comma separated list of allowed origins
Environment="OLLAMA_ORIGINS=http://1.2.3.4"
# Duration that models stay loaded in memory
Environment="OLLAMA_KEEP_ALIVE=5m"
- Save and exit
- Reload systemd and restart Ollama:
sudo systemctl daemon-reload
sudo systemctl restart ollama
The list of available configuration environment variables is available at https://github.com/ollama/ollama/issues/2941#issuecomment-2322778733
And additional configuration explanation is available at https://github.com/ollama/ollama/blob/main/docs/faq.md
API
Ollama provides a HTTP API endpoint (the bind address can be configured, see above).
⚠ to use a model, don’t forget to pull the model first:
ollama pull llama3.2
Once done, you can query the model, for example using curl:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "Why is the sky blue?"
}'
This will return the response tokens (words) one by one.
I you prefer to wait for the full answer:
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "Why is the sky blue?",
"stream": false
}'
More explanation about the API is available at https://github.com/ollama/ollama/blob/main/docs/api.md
Ollama now also offers an endpoint compatible with OpenAI API:
curl http://localhost:11434/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "llama3.2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Why is the sky blue?"
}
]
}'
This means that Ollama can be queried with any OpenAI compatible client library!
More about the OpenAI API: https://ollama.com/blog/openai-compatibility and https://platform.openai.com/docs/guides/text-generation
This blog post is licensed under
CC BY-SA 4.0


