Ceph distributed storage (part 2) : file storage performance
Apr 22, 2025 by Thibault Debatty | 3788 views
https://cylab.be/blog/412/ceph-distributed-storage-part-2-file-storage-performance
In a previous blog post I showed how to install and run a ceph distributed storage cluster. Now let’s have a look at performance when we mount a distributed file storage…
Expectation management
Well, first let’s do some expectation management. I’m going to measure the throughput and the number of IOPS that my distributed CEPH storage can achieve. Which kind of numbers should I expect?
According to CrystalDiskMark x64, when tested with 1 thread and a queue depth of 1, a high end consumer SSD like the Samsung 9100 PRO 2TB can achieve up to:
| Read (MB/s) | Write (MB/s | |
|---|---|---|
| Sequential (1M) | 9655 MB/s | 10551MB/s |
| Random (4K) | 88 MB/s (22000 IOPS) | 250 MB/s (or 62500 IOPS) |
https://www.servethehome.com/samsung-9100-pro-2tb-pcie-gen5-nvme-ssd-review/2/
For this demo, I’ll be using lower end drives, namely Crucial BX500 SATA SSD 480Go. According to my tests, these drives achieve the following performance:
| Read (MiB/s) | Write (MiB/s | |
|---|---|---|
| Sequential (1M) | 457 MiB/s | 437 MiB/s |
| Random (4K) | 59 MiB/s (14374 IOPS) | 239 MiB/s (or 61355 IOPS) |
But we will not evaluate here the performance of a drive attached directly to our system. The drives will be attached to multiple nodes interconnected by a classical Ethernet network. Hence we can expect less, but how much?
Cloud providers are confronted to the same situation, so they can provide us with some indications. For example, AWS General Purpose SSD (gp3) volumes offer:
a consistent baseline throughput performance of 125 MiB/s, which is included with the price of storage. You can provision additional throughput (up to a maximum of 1,000 MiB/s) for an additional cost at a ratio of 0.25 MiB/s per provisioned IOPS. Maximum throughput can be provisioned at 4,000 IOPS or higher and 8 GiB or larger (4,000 IOPS × 0.25 MiB/s per IOPS = 1,000 MiB/s).
So even the best gp3 volume can only offer roughly 1/10th of the throughput of the directly attached Samsung 9100 PRO.
Regarding IOPS, gp3 volumes offer:
a consistent baseline IOPS performance of 3,000 IOPS, which is included with the price of storage. You can provision additional IOPS (up to a maximum of 16,000) for an additional cost at a ratio of 500 IOPS per GiB of volume size. Maximum IOPS can be provisioned for volumes 32 GiB or larger (500 IOPS per GiB × 32 GiB = 16,000 IOPS).
So the situation regarding IOPS seems beter, although the documentation does not mention the number of threads or the queue depth required to achieve this results, and these can have a huge impact!
https://docs.aws.amazon.com/ebs/latest/userguide/general-purpose.html
Queue depth or queue length is the number of outstanding I/O requests that a storage device can handle at any one time. It represents the number of pending transactions to the drive, which can be thought of as the number of simultaneous requests on a drive’s request queue.
Queue depth can wildly influence the number of operations that occur per second, known as IOPS. Higher queue depth generally equates to better performance as it allows for more concurrent operations, reducing latency and increasing throughput.
At Scaleway, block storage is available in 2 ‘flavors’ : one that offers up to 5000 IOPS and the other up to 15000 IOPS.
https://www.scaleway.com/en/pricing/storage/#block-storage
So the question is, how much can we expect with commodity hardware?
Lab environment and testing
For this demo I used a small cluster of 3 nodes. Each node is actually a micro computer with 8GB of RAM, a 2.5G ethernet network interface and 2 SSDs: one 128GB SSD for the OS and one 480GB SSD reserved for Ceph data. So this is actually cheap domestic equipment, but enough to run a micro-cluster.

For the base OS I used Debian Bookworm server (so without a graphical environment).
To test storage performance I used a sysbench script which you can find on GitHub:
https://gist.github.com/tdebatty/0358da0a2068eca1bf4583a06aa0acf2
The script measures sequential read and write speed using block of 1 MiB, and random read and write with blocks of 4 KiB. In each case, there is a single thread running, and queue depth is 1.
As my nodes are interconnected by a 2.5Gbps Ethernet network, transfer speed will be limited by the network at
2.5 x 1000 / 8 x 95% = 296 MiB/s
Each test is executed 20 times, so I can compute the mean and standard deviation (std dev) of results.
The raw results and python notebook used to analyze the data are available at https://gitlab.cylab.be/-/snippets/5
Create a CEPH File System
To use CEPH as a distributed file system, we must create a user that will be allowed to mount, read and write the file system.
Create user
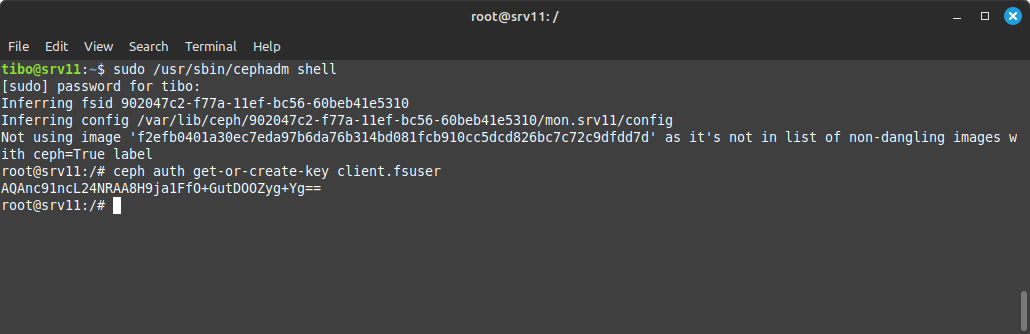
To create a Ceph user without specific capabilities, connect to master node and start the Ceph shell:
sudo /usr/sbin/cephadm shell
You can now create a user and get the user key (secret) with
ceph auth get-or-create-key client.<username>
If needed, you can also get the key of an existing user with:
ceph auth print-key client.<username>
Create File System
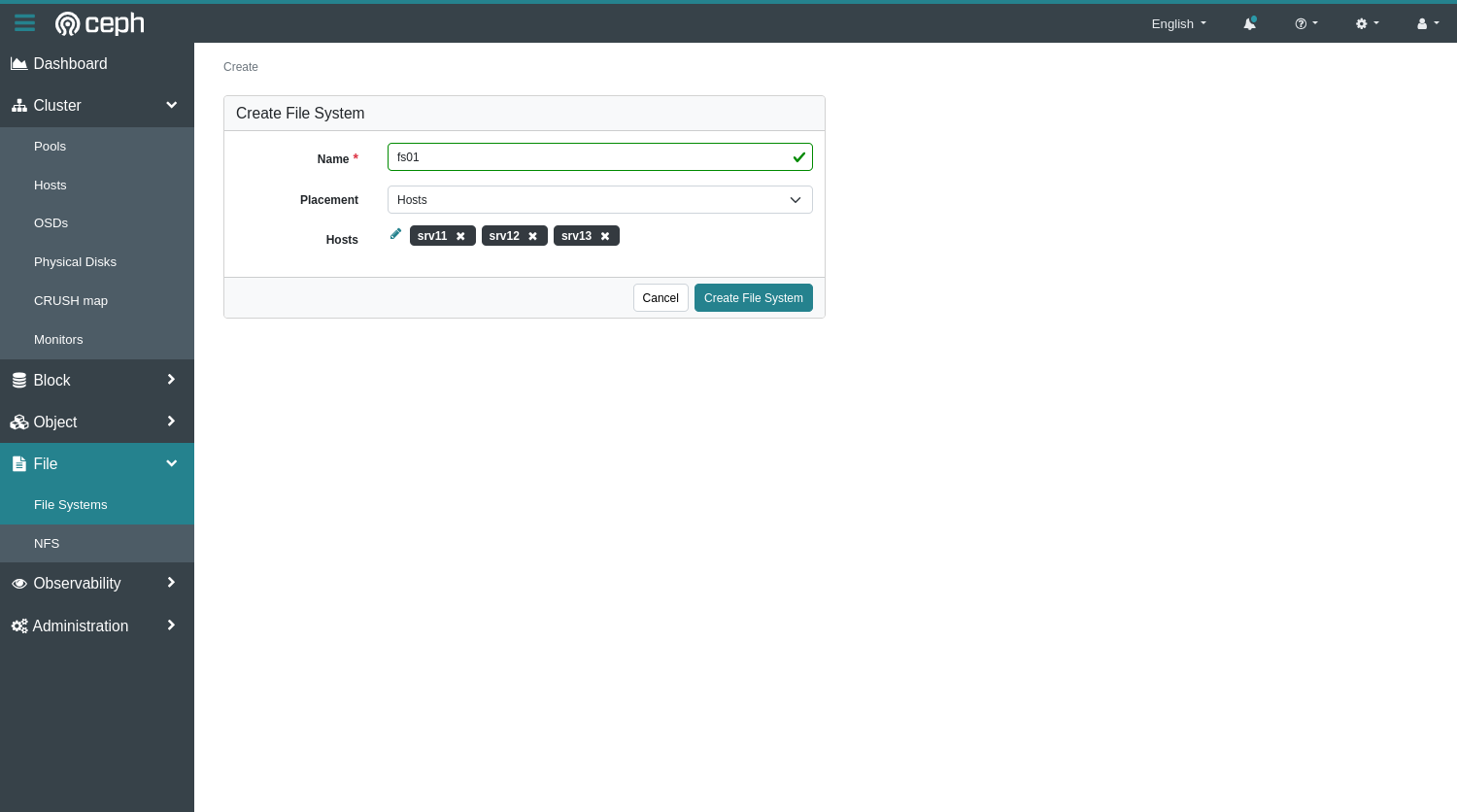
To create the File System, we can simply use the web interface. Open File then File Systems and click on Create. In the dialog that appears you can choose where the data will be stored. You would typically use tags for this purpose, but for this example I simply selected my 3 nodes…
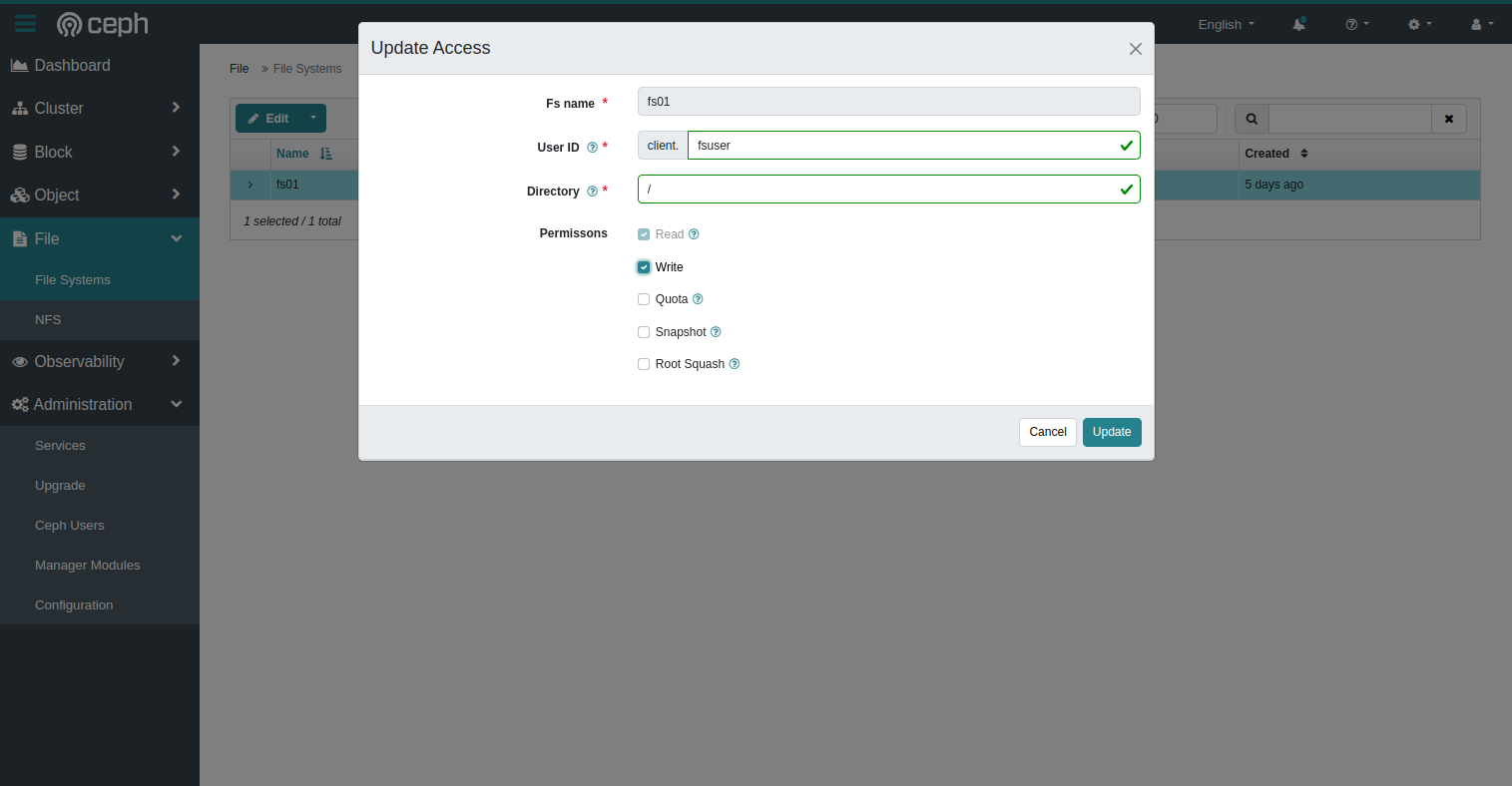
When the FS is created, we must allow our user to mount and use it.
- Select the freshly created file system
- In the menu at the top, select
Authorize - Fill the fields as required
Mount the File System
Now that all pieces are in place, we can finally mount and use the distributed file system.
On the client machine, make sure Ceph tools are installed:
sudo apt install ceph-common
You can now mount the file system with:
sudo mount -t ceph <mon>:/ <mountpoint> -o name=<username>,secret=<secret>,mds_namespace=<fsname>
where:
usernameis the name of the user we just created (without theclient.);fsnameis the name of the file system you created;mountpointis the location where the fs must be mounted (on the local file system);monis the ip (and port) of the monitors separated by a comma andsecretis the secret key of the user.
For example:
sudo mount -t ceph 192.168.178.11,192.168.178.12,192.168.178.13:/ /mnt/fs01 -o name=fsuser,secret=AQAnc91ncL24NRAA8H9ja1FfO+GutDOOZyg+Yg==,mds_namespace=fs01
Distributed File System Performance
We can now run the sysbench script to measure the performance of my distributed file system. Here are the values after 20 iterations:
Throughput (MiB/s)
| Read Mean | Std Dev | Write Mean | Std Dev | |
|---|---|---|---|---|
| Sequential (1M) | 232 MiB/s | 10.2 | 109 MiB/s | 39 |
| Random (4K) | 0.00 MiB/s | 0.00 | 64 MiB/s | 10.97 |
IOPS
| Read Mean | Std Dev | Write Mean | Std Dev | |
|---|---|---|---|---|
| Sequential (1M) | 233 | 10 | 110 | 39 |
| Random (4K) | 59 | 2.88 | 16715 | 2791 |
There are clearly some interesting conclusions here:
- for sequential read, we can almost saturate the 2.5G Ethernet switch
- write speed is much more variable than read speed
- random (4K) write ispeed is very good
- but random (4K) read speed is catastrophically slow!
There is one parameter that has a large impact here: the rasize (read ahead size, in Bytes) mount option which, as the name states, will actually read more data from the distributed storage than what is actually required. This can largely improve sequential read performance, at the expense of small random reads.
According to CEPH documentation, the default rasize value is 8MiB, much larger than the size of read operations during random read tests. So I repeated the test with mount options rasize=0 and rasize=4096
https://docs.ceph.com/en/reef/man/8/mount.ceph/
Throughput (MiB/s), rasize=0
| Read Mean | Std Dev | Write Mean | Std Dev | |
|---|---|---|---|---|
| Sequential (1M) | 5.6 MiB/s | 0.88 | 119 MiB/s | 3103 |
| Random (4K) | 5.2 MiB/s | 0.41 | 72 MiB/s | 11.45 |
IOPS, rasize=0
| Read Mean | Std Dev | Write Mean | Std Dev | |
|---|---|---|---|---|
| Sequential (1M) | 6 | 0.83 | 120 | 31.43 |
| Random (4K) | 1476 | 67 | 18535 | 2937 |
Throughput (MiB/s), rasize=4096
| Read Mean | Std Dev | Write Mean | Std Dev | |
|---|---|---|---|---|
| Sequential (1M) | 100 MiB/s | 6.87 | 109 MiB/s | 38.86 |
| Random (4K) | 5.20 MiB/s | 0.52 | 53.85 MiB/s | 12.37 |
IOPS, rasize=4096
| Read Mean | Std Dev | Write Mean | Std Dev | |
|---|---|---|---|---|
| Sequential (1M) | 100 | 6.88 | 110 | 38.79 |
| Random (4K) | 1449 | 106 | 13874 | 3165 |
We can indeed see that IOPS for random read operation is largely improved, while sequential read performance drops, especially if read ahead id deactivated (rasize = 0), so a trade-off must be found between sequential and random read speed…
Read ahead size (rasize) must be set to find a trade-off between sequential and random read speed.
With a large read ahead size, we can almost saturate the 2.5G Ethernet switch when performing sequential read.
Moreover, in both case random write speed remains much faster than random read.
Conclusion
In this blog post, we explored the performance of a Ceph distributed storage cluster when used as a file system. We compared the expected performance of commodity hardware to that of high-end consumer SSDs and cloud provider offerings. Our test results showed that with our commodity hardware cluster, the Ceph distributed file system achieved:
- Sequential read speeds of up to 232 MiB/s and write speeds of up to 109 MiB/s
- IOPS of up to 1449 for sequential read and 16715 for sequential write
Overall, our results suggest that a Ceph distributed file system can provide good performance for sequential read and write operations, but may struggle with small random reads. However, with careful tuning of the rasize mount option, it is possible to achieve good performance for both sequential and random read operations.
<TL;DR>
Use a large read ahead size (rasize) to achieve good sequential read performance. In our case we could almost saturate the 2.5G Ethernet switch when performing sequential read.
Use a small read ahead size (rasize) to improve random read performance.
This blog post is licensed under
CC BY-SA 4.0


